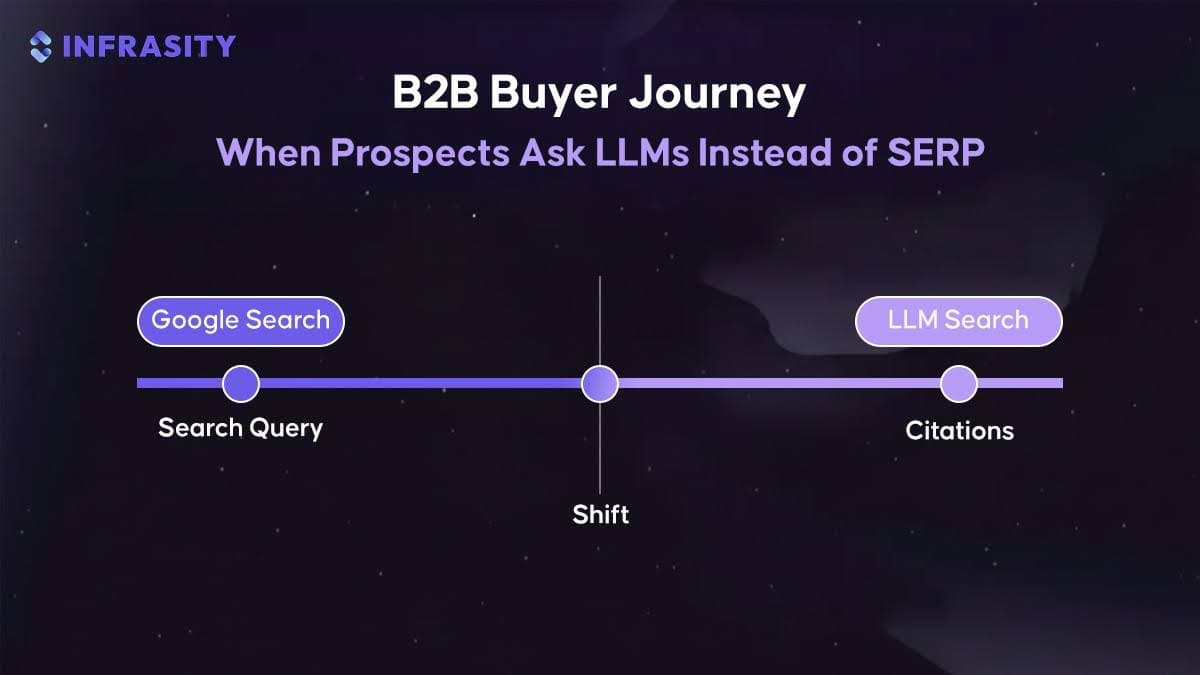
Introduction
Robots.txt is an amazing tool to help you better optimize your website and increase its ranking. You just have to add a robot.txt command to your URL and voila! a whole lot of problems are solved.
Robots.txt is a simple text file that helps guide search engine crawlers and ensures they focus on what matters most for your SEO.
So, If you've ever wondered how search engines decide which pages of your website to show in search results and which ones to ignore, the answer lies in the guideline issued by robots.txt.
Without robots.txt, search engines could end up wasting time crawling irrelevant pages, such as duplicate content or private areas of your website that aren't meant for public viewing. This can lead to a wasted crawl budget, poor indexing, or even the exposure of sensitive information.
By learning how to use and optimize robots.txt, you can take control over how your website is crawled and indexed---ultimately improving your SEO results and protecting your content. Robot txt in SEO is a gamechanger tool which can significantly add to your websites growth.
What is Robots.txt?
Robots.txt is a plain text file that lives on the root of your website and gives web crawlers instructions about which parts of your site they can access and which are off-limits.
Imagine Robots.txt like an instruction guide for the guest coming to your house. They are allowed access to your living room but the bedroom is off bounds. The guest in this case being the web crawlers bots.
The job of these web crawler bots is to ‘crawl’ (access the website and learn what it is about) the website and index it so that it can pop up on the SERF page. To simplify the work of these bots and get the most optimum ranking, robots.txt is used.
A robots.txt file on your website instructs a user agent (web crawling bot) whether to crawl or not crawl part of your website. It functions through ‘allowing’ and ‘disallowing’ the user agent.
How Does Robots.txt Work?
When a search engine crawler (like Googlebot) visits your site, it first checks your robots.txt file for instructions. These instructions help it decide where to go and what to skip.

If your website does not have any robot.txt, the crawler will begin crawling all the available content on your site.
Here's where it's usually found:
For example, if your website is https://example.com, your robots.txt file would be at https://example.com/robots.txt.
So, what does adding the robot.txt do?
- Keep sensitive pages private: If you have an admin login page or a draft folder that you don't want search engines to index, robots .txt can block access to those.
- Saves time and resources: It tells crawlers to focus on important areas, like your blog or product pages, instead of wasting time on irrelevant sections.
Even though it's just a simple text file, it's a critical part of your website's SEO strategy.
Robots.txt Guide for Commonly Used Directives
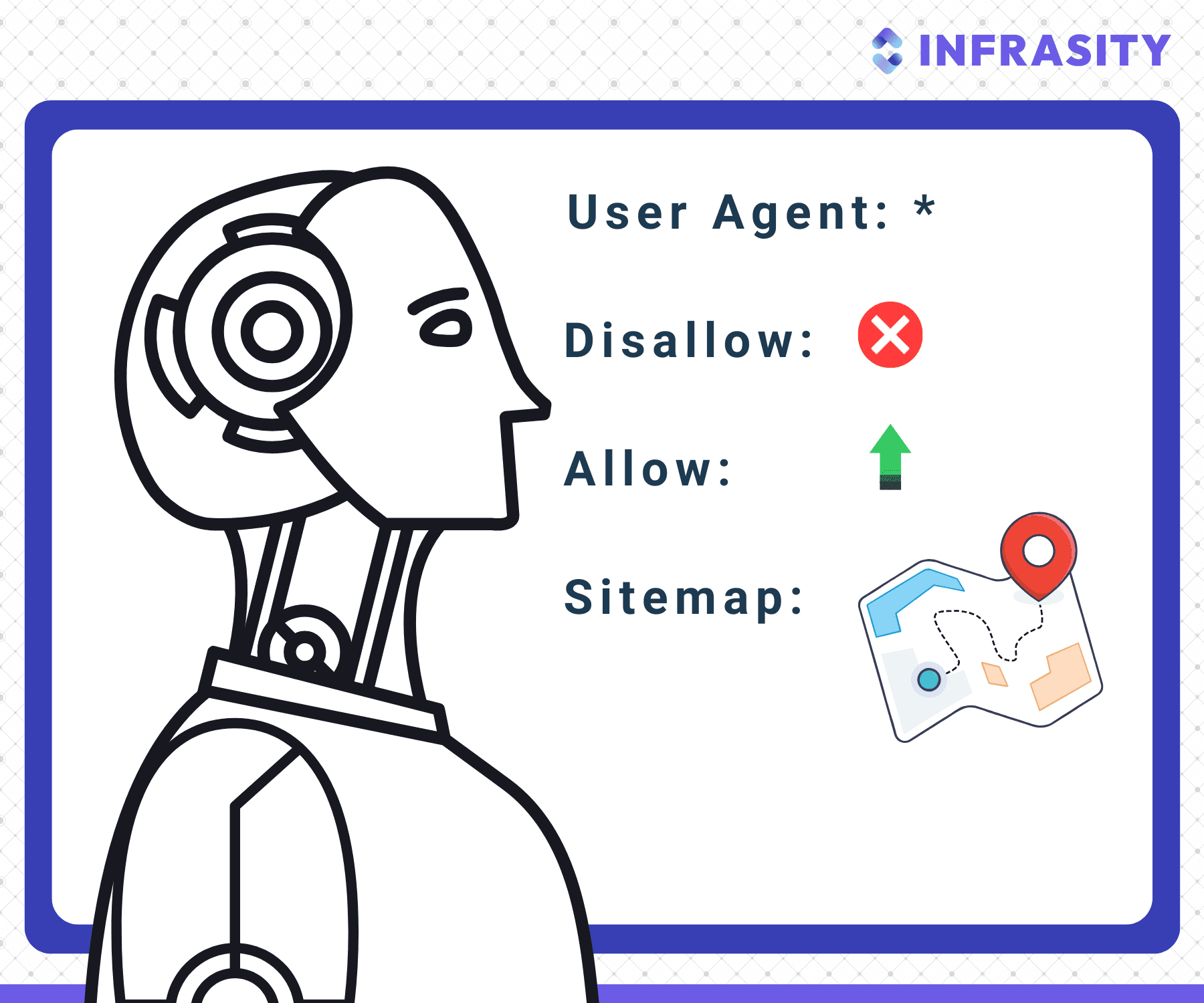
1. What is User Agent?
The user-agent in a robots.txt file identifies which web crawler the directives apply to. The user-agent is the name of the spider that the directives are for. So, for instance, if you want your website to pop up when you do a google search but not when you do yahoo search, a robot.txt comes in handy.
User agents aren't limited to traditional search bots anymore. AI crawlers that power chatbots and answer engines now index your site too, so the pages you allow them to reach directly affect whether your content gets surfaced as a direct answer. This makes it worth understanding Answer Engine Optimization (AEO) alongside your robots.txt setup, since letting the right crawlers reach your best content is a prerequisite for showing up in AI-generated answers.
The robot.txt instruction for a bot user agent to show up your website on a google search is :
User-agent: Googlebot
Allow: /And, if you do not want it to show up on a bing search, the robot.txt instruction is:
User-agent: Bingbot
Disallow: /2. What is a Disallow Command on Robot.txt?
The Disallow command is the most used directive in robot.txt. It tells the web crawler not to crawl a particular part of the website, such as specific pages or folders.
So, for instance if your product is a bag and you want it to show up on a google search. The web crawler will be allowed to access it, in order to index it and therefore it will show up when you search for it. But you do not want your bag added to the cart by customers, also pop up when someone searches for it. Thus, to disallow web crawler from crawling an item added in cart on, say, amazon you will have to write a robot.txt file that disallows web crawlers from accessing URLs related to a shopping cart on Amazon:
User-agent: *
Disallow: /cart
Disallow: /gp/cart/
Disallow: /cart/viewOn the other hand, the allow command grants access to specific files, even if their folder is disallowed. The "Allow" directive overrides a "Disallow" rule for specific files or sub-directories. So, even if a broader path is blocked, you can use "Allow" to let certain pages through.
3. What is Crawl Delay in Robot.txt?
In the robot.txt file of the website, there are instructions regarding the frequency with which the crawler can access pages on your site. The administrator can issue instructions to the crawler to wait a specific amount of time, in milliseconds, before crawling each page. This directive is called crawl delay in robot txt and it is used to not overburden the web server.
For instance, if you want the web crawler to crawl pages at an interval of 10 seconds, use the command:
User-agent: *
Crawl-delay: 10Buzzfeed uses a crawl delay of 10 ms.
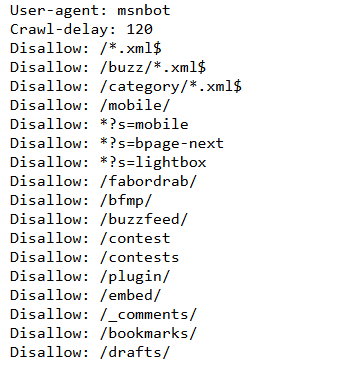
This means that search engine crawlers should wait 10 seconds before requesting another page from your site, helping your server handle the load more efficiently.
However, some browsers like google do not obey the crawl delay command, but yahoo and bing do.
4. What is Sitemap in Robot.txt?
The sitemap in robot.txt is a list of all pages on a website that the bot has to crawl. It lists all the important pages on your website and therefore helps the crawler in indexing your website more quickly and efficiently. Its job is also to ensure that the crawler does not miss any pages and understand your website structure.
What Happens if There's No Robots.txt File?
If your website doesn't have a robots.txt file, crawlers assume they can access everything. This might sound okay, but it could lead to:
- Crawlers waste time on pages that don't add value, like duplicate content or utility pages (e.g., cart or checkout pages).
- Sensitive information is accidentally being indexed.
By setting up a well-structured robots.txt file, you can ensure search engines focus on the right areas, giving your technical SEO strategy the boost it deserves.
Why is Robots.txt Important for SEO?
A robots.txt file can make or break your site's SEO performance. By using it wisely, you can ensure that search engines focus on the right content and ignore what doesn't need to be indexed.
It's worth noting that robots.txt is a crawling control, not a content strategy on its own, so it works best alongside the rest of your optimization efforts. If you're weighing where to invest next, our breakdown of AEO vs SEO explains how classic ranking-focused SEO and answer-engine optimization complement each other, and why a well-configured robots.txt file supports both.
Here's how it can help:
1. Control Crawl Budget
Every website has a limited amount of resources, and search engines like Google have a limited "crawl budget" - the amount of time and resources they'll spend crawling your site.
If your site has a lot of pages, but some are more important, robots.txt helps guide the crawler to focus on the important ones and block other low priority pages from being crawled.
For example, SaaS companies often have outdated product pages that no longer provide much value. By blocking these pages from being crawled, you free up the crawl budget for more important pages, like the ones showcasing your current features.
2. Prevent Duplicate Content
If you have several versions of the same page on your site - perhaps one with a query parameter (like "?ref=123") and another without, search engines might see these as separate pages, and crawl them separately.
Robots.txt can block these duplicate pages from being crawled, helping search engines focus only on the original page and improving your site's SEO.
Once you've cut out duplicate URLs, the pages that remain need to be genuinely distinct in the eyes of a search engine, not just at different addresses. Working through our LSI Keywords Guide can help you write content for each surviving page with related, contextually relevant terms, so crawlers see each URL as covering a unique topic rather than a near-duplicate of another page on your site.
3. Protect Sensitive Information
Your website might have areas not meant for public viewing, like test environments, internal dashboards, or private documents. Robots.txt allows you to block crawlers from accessing these areas, helping protect sensitive information and keeping it from being indexed on search engines.
4. Blocking Test or Staging Environments
If you're working on a new website version or testing changes in a staging environment, you don't want search engines to crawl these "unfinished" pages. Robots.txt can help prevent these test pages from appearing in search results until your site is ready to go live.
By using the various robot.txt directives wisely, you can give search engines clear instructions on which pages to crawl and which to ignore, ensuring your website is optimized for better SEO.
Common Robots Txt File Examples
Let's take a closer look at common robots.txt examples which can be effectively used in real-world scenarios to optimize SEO and improve site crawlability:
1. Blocking Internal Search Pages
Many websites, especially e-commerce or content-heavy sites, use internal search functionality.
However, URLs generated by internal searches, like https://www.example.com/?s=search-term, can lead to endless crawling of non-essential pages. Blocking these URLs in robots.txt is crucial to prevent search engines from wasting crawl budgets on irrelevant content.
To block search URLs, you can use the following:
User-agent: *
Disallow: *s=*This rule ensures that search engines block any URL with ?s=(typically used for search parameters) from crawling.
2. Blocking Faceted Navigation URLs
For e-commerce sites, faceted navigation often generates multiple URLs for the same products, causing duplicate content issues. For example, filtering products by color, size, or price could result in hundreds of duplicate pages.
To prevent this, you can block these specific filter URLs:
User-agent: *
Disallow: *color=*
Disallow: *size=*
Disallow: *price=*By doing this, you ensure search engines focus on the most important pages rather than crawling countless variations of the same content.
3. Blocking PDF URLs
Some sites may host PDFs, such as product manuals or guides, which may not add much value to search rankings.
To avoid these PDFs being crawled, you can use:
User-agent: *
Disallow: /*.pdf$This rule blocks all PDF files across the website from being indexed by search engines, thus optimizing the crawl budget.
4. Specifying Sitemap URLs
To make it easier for search engines to discover all the important pages on your website, like technical product documentation, you can specify the location of your sitemap(s) in the robots.txt file:
Sitemap: https://www.infrasity.com/sitemap.xml
This helps ensure that search engines have easy access to all the URLs that are important for SEO.
Robot.txt vs Meta Robots Tags vs Directive No Index Tags
robots.txt is primarily used for blocking entire sections or pages from being crawled. On the other hand, meta robots tags function within individual pages and allows for more precise control over which part of pages are crawled or indexed. A small variation in these robots is directive no index robots.txt tags, which goes one step ahead and prevents content from appearing on the search page and hence is not crawled.
Common Robots.txt Mistakes and Solutions
When working with robots.txt, it's essential to avoid common mistakes that can negatively impact your website's SEO.
Here are some common robots.txt mistakes and solutions to help you optimize your website's crawling process.
1. Blocking the Entire Site by Mistake
One of the most common mistakes when configuring robots.txt is accidentally blocking the entire website from search engines.
This can happen if you add a rule like this:
User-agent: *
Disallow: /This would tell all search engines to avoid crawling every page on your site, which can prevent your website from appearing in search results. To avoid this, it's important to regularly check your robots.txt file using tools like Google Search Console to ensure nothing important is being blocked.
2. Not Making Regular Updates to Your Robot.txt File
The content and structure of your website evolves regularly. Your robot.txt file should also be updated regularly to reflect the changes in your website.
Further, If you've been testing your site on a staging environment (a testing version of your website), you might have set up a rule to block crawlers from accessing that staging site. However, after launching the site, you must remember to update or remove these rules.
If you don't, search engines might still be blocked from crawling your live website, affecting your SEO.
How to Test and Validate Robots.txt
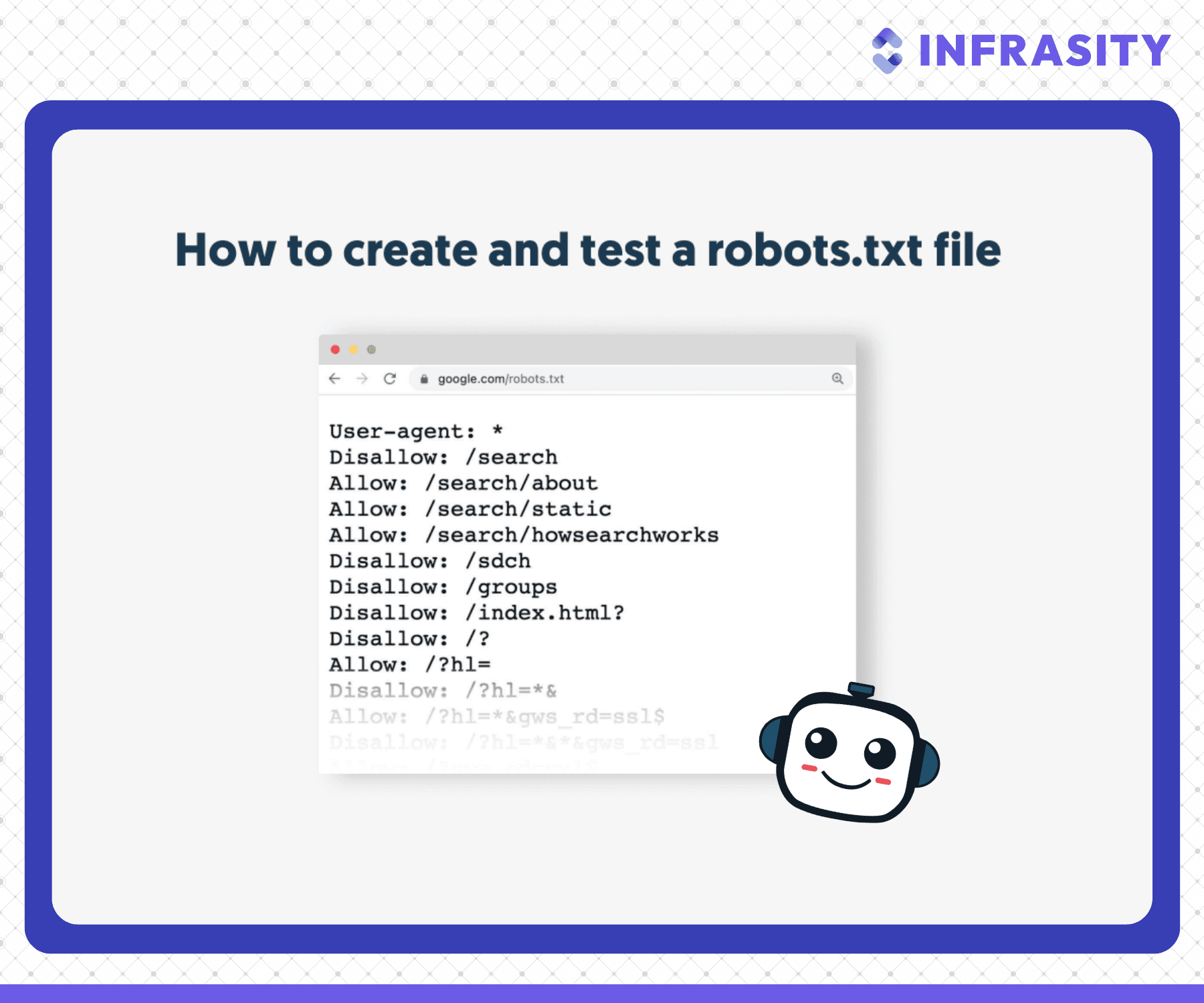
When creating or updating your robots.txt file, testing and validating it is essential for ensuring it works as intended.
Here's how you can test and validate your robots.txt for optimal SEO performance.
- Use Google Search Console's Robots.txt Tester: Google Search Console provides a Robots.txt Tester that helps you test your robots.txt file. It checks if your directives are correctly blocking or allowing the intended pages and will highlight any potential issues.
- Use Screaming Frog: Screaming Frog is another powerful tool for testing robots.txt. It helps you analyze how your site's pages are being crawled and whether any pages you want to crawl are accidentally being blocked.
Steps to Test Your Robots.txt File:
Step 1: Upload your robots.txt file to your server -- Make sure it's available at https://www.infrasity.com/robots.txt.
Step 2: Use testing tools, such as Google Search Console's tester or Screaming Frog, to verify that your rules are functioning correctly.
Step 3: Adjust your syntax based on the results -- If any pages are blocked unintentionally, you can fix the rules and test again.
Conclusion
In conclusion, robots.txt is an essential tool for controlling how search engines interact with your website. Its role in SEO cannot be overstated, as it helps ensure search engines crawl only the most important pages, prevents duplicate content issues, and protects sensitive data. Regular testing and updating of your robots.txt file are crucial to keeping your SEO strategy aligned with your business goals.
To maximize your SEO efforts, combine robots.txt with other technical SEO tools like meta tags, sitemaps, and Google Search Console. This will give you more precise control over indexing your content and enhance your overall website performance.
Want to take your SEO strategy to the next level? Let Infrasity guide you with expert tips and tools to optimize your website's performance.
Explore our services today and ensure your website is fully optimized for search engines and ready to achieve top rankings.
Frequently Asked Questions
1. What Does "Disallow" Mean in Robots.txt
The Disallow directive in a robots.txt file tells web crawlers which parts of the website they should not access or crawl. For example, if you want to prevent crawlers from indexing your private.html page, you would add:
User-agent: *
Disallow: /private.html2. Can a Bot Ignore the Robots.txt File?
Yes, while most search engine bots follow the instructions in the robots.txt file, some bots, particularly malicious ones, may choose to ignore it. Thus, there are good bots and bad bots. The former, such as a web crawler, obeys the instructions issued by the robot.txt file.
3. Is Robot.txt Good for Seo
Robot.txt helps crawlers navigate your website. So, in a lengthy website, a robot.txt file will specify what pages to crawl, thereby making navigation on your site easier for the bot. This will make it rank better on the SERF.
4. What is Robot.txt Used for
Robot.txt is a simple text file that can be added to your website URL to help the web crawler bot navigate your website more efficiently. It instructs the bot not to crawl unnecessary pages. It therefore prevents overloading the crawler.
5. How Do You Manually Overwrite the Robots.txt File in Wordpress?
Typically, wordpress creates a robot.txt file for your website by default. But it also offers a feature to customize or update the robot.txt command manually. To do so, access the root directory of your website via file manager. Do your desired edits with robot.txt directives such as (allow, disallow, sitemap). Save the changes and upload the file back.